
『大数据基础』11-大数据计算:Spark为什么更快(计算原理)
一、MapReduce执行复杂计算场景
从MapReduce编程模型中可以看到,一个MapReduce程序最多只包含一个map方法和一个reduce方法。但是在复杂计算场景中,往往不止一次的MapReduce就能得到最终结果,有可能需要循环执行多次甚至数万次MapReduce(比如回归任务),也有可能多个不同逻辑的MapReduce前后执行才能得出最后结果。这时候需要前面reduce的结果暂存到HDFS中,下一次的map到HDFS读取这个数据作为输入。
这样会产生两个问题:
复杂计算场景下多次MapReduce中间数据的传递会造成频繁的分布式集群磁盘I/O;
多个MapReduce的执行需要依赖作业调度框架来安排执行次序,形成拓扑关系。
二、Spark执行复杂计算场景
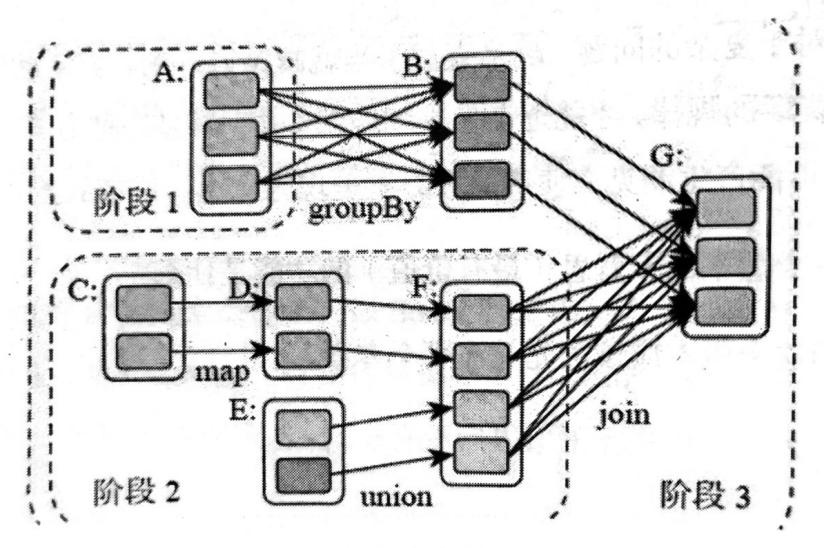
图1 计算阶段组成DAG
(一)计算阶段和执行DAG
同样的复杂计算场景,Spark会比MapReduce快得多。Spark可以在一个程序里完成整个复杂场景的计算逻辑设计,而不需要像MapReduce那样需要启动多个应用。Spark将整个复杂的计算过程分割成多个计算阶段(stage),计算阶段的划分并不是像MapReduce那样在程序设计时就固定了map阶段和reduce阶段,而是底层引擎根据应用程序自动划分。这些计算阶段组成一个执行DAG,Spark任务调度器根据DAG的拓扑关系来执行这些计算阶段。
图1对应的Spark程序是:
rddB = rddA.groupBy(key)
rddD = rddC.map(func)
rddF = rddD.union(rddE)
rddG = rddB.join(rddF)Spark作业调度的核心是有向无环图DAG,调度的作业单元是DAG结点(即计算阶段stage)。根据每个stage要处理的数据量生成相应的任务集合(TaskSet),并给每个任务分配一个任务进程进行处理。
负责生成和管理DAG的是DAGScheduler组件,它生成DAG后将程序分发到分布式计算集群,按计算阶段拓扑关系进行计算。
(二)计算阶段划分依据
计算阶段划分的依据是shuffle,每次shuffle都会产生新的计算阶段。如图1中rddA生成rddB经过shuffle,产生新的计算阶段。rddF生成rddG经过shuffle,产生新的计算阶段。
灵性理解:shuffle重新组合数据,RDD分片需要在集群中进行分区传输,写入到另一个RDD分片中形成新的分片。在两次shuffle之间RDD分片不需要分区传输,在物理上并未产生新的分片。因此两次shuffle之间的操作可以看作对同一个数据集对象的操作,也就是计算阶段。
(三)窄依赖和宽依赖
窄依赖:像图1中rddC到rddD等不需要shuffle的依赖;
宽依赖:像图1中rddB和rddF到rddG等需要shuffle的依赖。
三、Spark更快的原因
MapReduce有两个过程的中间数据是存储在HDFS磁盘上的:
MapReduce简单粗暴地根据shuffle将大数据计算划分成map阶段和reduce阶段,基本每个程序都有这固定两个阶段。同一个程序里map和reduce的中间数据,通过上下文对象(context)读写,实际是落在HDFS的,shuffle时实际需要经历读、传、写的过程;
前一个reduce和下一个map的中间数据,也需要前一个reduce先写HDFS,下一个map再读取。
Spark则有效地避免了这两种的I/O开销:
Spark优先使用内存存储数据,包括RDD数据,除非内存不够。因此就避免了MapReduce的第一个麻烦;
Spark计算阶段的划分更细腻,两个真正的shuffle操作之间的操作看成一个执行的整体,即计算阶段,相当于把前后的reduce和map连起来了,减少了很多无谓的中断、读写等开销。
(整理自《大数据技术架构:核心原理与技术实践》)













