
『大数据基础』06-大数据计算:MapReduce作业执行机制(Hadoop 1)
前文提到“MapReduce既是编程模型,也是计算框架”。在Hadoop 1中其作为计算框架时负责在分布式系统中调度程序和资源进行计算。但是在Hadoop 2中MapReduce资源调度的功能就被拆分出来形成了Yarn框架。因此本文的MapReduce作业执行机制仅限于Hadoop 1。
一、MapReduce作业调度的三类进程
(一)大数据应用进程
大数据应用进程类似于Spring Boot里面的Application,是MapReduce程序的主入口。它主要指定Map类和Reduce类、输入输出文件路径等,即定义好Map过程和Reduce过程应该要做什么,定义好数据资源的位置等。用户遵循MapReduce编程模型写好Map和Reduce程序后,大数据应用进程将作业打包成jar包并作为文件存储HDFS集群中,而后提交作业给JobTracker进程在HDFS集群中具体调度执行。
(二)JobTracker进程
JobTracker进程在作业调度过程中是集群全局唯一的,它的作用是进行作业生命周期的调度和监控。通过向所有相关的运行在DataNode服务器上的TaskTracker进程分发任务,告知其需要处理多少数据,需要启动多少个Map进程和Reduce进程,需要做什么运算操作。
(三)TaskTracker进程
TaskTracker进程和DataNode进程一样,都在存储数据的服务器节点中运行,占用的是单个节点的计算资源。TaskTracker进程负责具体创建和管理Map进程和Reduce进程。JobTracker进程和TaskTracker进程是主从关系。
二、MapReduce作业调度完整过程说明
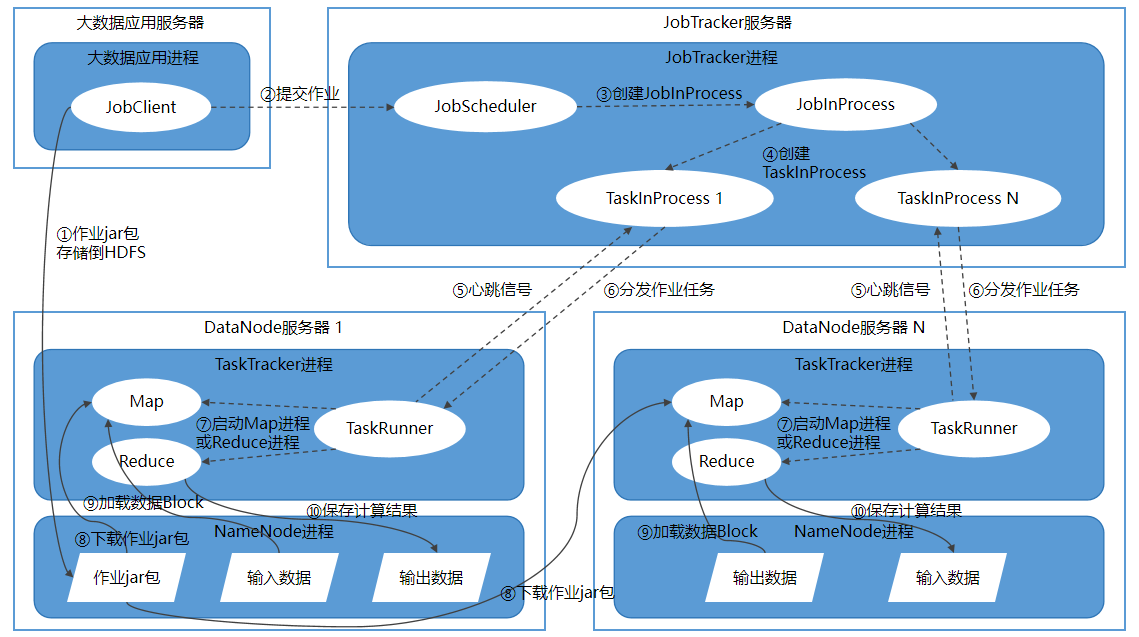
图1 Hadoop 1的MapReduce计算框架作业调度运行机制
以下通俗的语言完整描述一遍作业调度的过程:
开发者遵循MapReduce编程模型为特定的大数据处理场景写好了处理程序,包含map过程和reduce过程的处理逻辑,并打包成作业jar包。大数据应用进程JobClient首先将作业jar包存储到HDFS,以供后续各个计算节点前去下载程序。
JobClient将作业任务提交给JobTracker进程,让JobTracker去调度、监控作业的执行。
JobTracker进程的JobScheduler专门用于接收提交过来的作业,为作业生成调度策略,并根据作业调度策略创建JobInProcess树(作业处理树),每个作业都会有一个自己的JobInProcess树。
JobInProcess根据输入数据的分片数量(数据块数量)和要设置的Reduce过程数量来创建合适数量的TaskInProcess进程,这些TaskInProcess进程用来一对一调度、监控TaskTracker进程执行作业的过程。
TaskTracker进程通过心跳信号告知JobTracker进程它状态正常,可以接受任务。
如果检测到TaskTracker进程可用并有空闲计算资源,对应负责的TaskInProcess会给它分配任务,TaskTacker进程里的的TaskRunner接收任务。每个TraskTracker进程只处理所涉及到的本机上的数据块分片。
TaskRunner负责具体创建和调度子进程(Map进程和Reduce进程),根据任务类型(Map / Reduce)和任务参数(JAR包路径、输入数据文件路径、数据在文件的起始位置和偏移量等),启动合适数量的Map进程或Reduce进程。
Map进程或Reduce进程检查本地是否有作业jar包,没有就到HDFS集群中下载。
Map进程读取本地数据块作为数据输入,根据作业jar包逻辑进行运算,运算结果将临时保存到本地数据块中,再由MapReduce计算框架自动进行的Shuffle进程分发到合适的节点作为后续的Reduce进程的输入。
Reduce进程读取输入数据并根据jar包逻辑进行运算后,保存计算结果到本地数据块。
(整理自《大数据技术架构:核心原理与技术实践》)













