
『大数据基础』09-数据仓库:Hive让MapReduce优雅地实现SQL操作
一、Hive诞生的原因
MapReduce编程模型已经极大简化了数据编程的难度,但还是不够简单,每次要针对性地写MapReduce程序。对于数据分析师来说,能直接使用已经烂熟的SQL最好不过。由此诞生了工具:Hadoop大数据仓库Hive(Facebook于2008年发布)。
二、Hive架构原理
Hive能够直接处理输入的SQL语句(注意:Hive的SQL语法和数据库标准SQL语法略有不同),调用MapReduce计算框架完成数据分析操作。
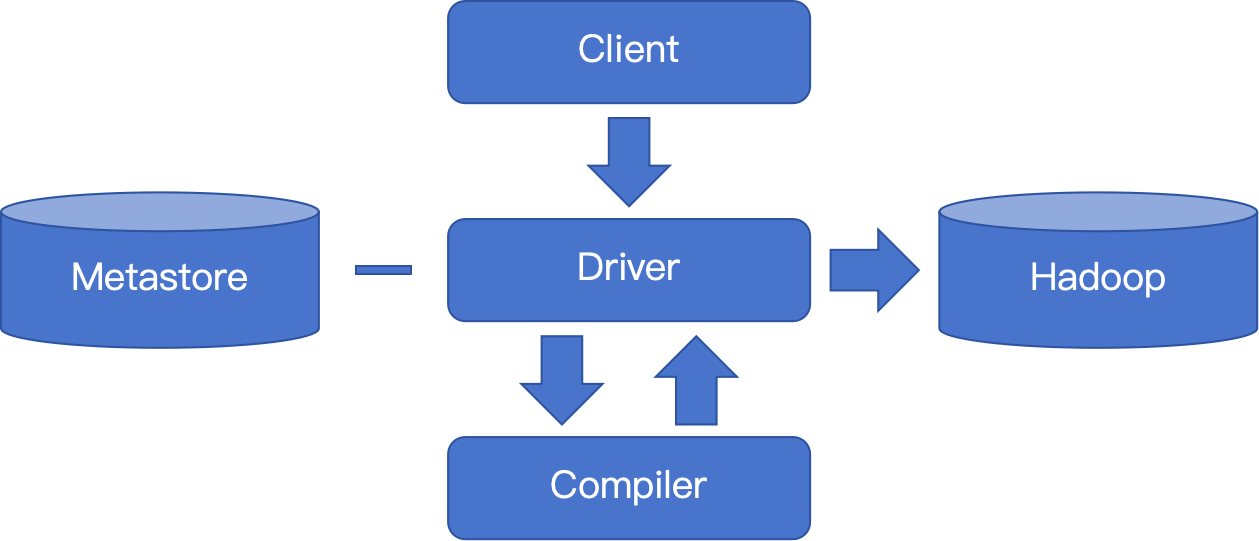
图1 Hive架构图
执行引擎Driver:接收客户端的SQL,存取元数据,或编译生成MapReduce作业提交到大数据集群执行后返回SQL结果给Client。
元数据Metastore:此组件通常用一个关系数据库实现,用来存储逻辑数据表的元数据信息,如表名、字段名、字段类型、关联HDFS文件路径等信息。
编译器Compiler:根据输入的SQL和元数据,编译优化生成MapReduce执行计划返回给执行引擎。
对于DDL(数据定义语句)SQL,如创建数据表的SQL,Hive并不会真正地创建关系型数据表而只会从逻辑上建表,它通过Driver将数据表信息记录在Metastore中。
对于DQL(数据查询语句)SQL,Hive通过Driver提交给Compiler进行编译,生成MapReduce执行计划;Driver再根据执行计划生成MapReduce作业提交给MapReduce计算框架执行。
三、Hive如何生成执行计划
HIve将SQL编译成MapReduce执行计划的核心,是通过内置的多种处理函数,根据SQL的语义生成函数的DAG图,封装进map函数和reduce函数中。内置的函数包括但不限于TableScanOperator、FilterOperator、FileOutputOperator。
四、其他的大数据SQL引擎
Impala:Cloudera开发的运行在HDFS上的MPP架构的SQL引擎。在一些统计场景中,Impala可以实现毫秒级的计算速度。
Spark SQL(前身是Shark):将SQL解析成Spark的执行计划。
Hive on Spark:专门用于兼容Spark计算框架,将Hive执行计划转换成Sprk的计算模型的SQL引擎。
(整理自《大数据技术架构:核心原理与技术实践》)













