
『大数据基础』10-大数据计算:另一种更快的计算框架Spark
一、Spark实现词频统计
Spark拥有更快的执行速度和更简单易用的编程模型。同样是词频统计任务,Spark只需要以下几行代码,而不用像MapReduce一样写很长的map函数和reduce函数:
val textFile = sc.textFile(“hdfs://...”)
val counts = textFile.flatMap(line => line.split(“ “))
.map(word => (word, 1))
.reduceByKey(_ + _)
counts.saveAsTextFile(“hdfs://...”)二、Spark核心原理
(一)弹性数据集RDD
Spark的核心概念是RDD(弹性数据集,Resilient Distributed Datasets),同时RDD也是面向开发者的编程模型。RDD就是将大数据集合抽象成一个对象,然后在这个对象上进行各种运算。
和MapReduce一样,Spark也是对大数据进行分片(数据块)计算的。Spark分布式计算的数据分片、任务调度都是以RDD为单位展开的,每个RDD分片都会分配到一个执行进程去处理。
(二)转换函数和执行函数
RDD上定义了两种函数:
转换函数(transformation):返回值还是RDD。有:
计算map(func)
过滤filter(func)
合并数据集union(otherDataset)
根据Key聚合reduceByKey(func, [numPartitions])
连接数据集join(otherDataset, [numPartitions])
分组groupByKey([numPartitions])等等;
执行函数(action):不再返回RDD。有:
count()返回RDD中元素个数
saveAsTextFile(path)将RDD数据存储到path路径下等等。
(三)惰性计算
Spark程序中逻辑上的RDD和执行过程中生成的RDD并非一一对应。上节提到的转换函数会返回值是RDD,但物理上并不一定出现新的RDD。Spark只有在产生新的RDD分片时才会从物理上真的生成一个RDD,这种特性叫惰性计算。
是否产生新的RDD分片,并不是依据诸如map(func)等转换函数的名称判断,而是根据底层逻辑判断的。
三、Spark大数据生态体系
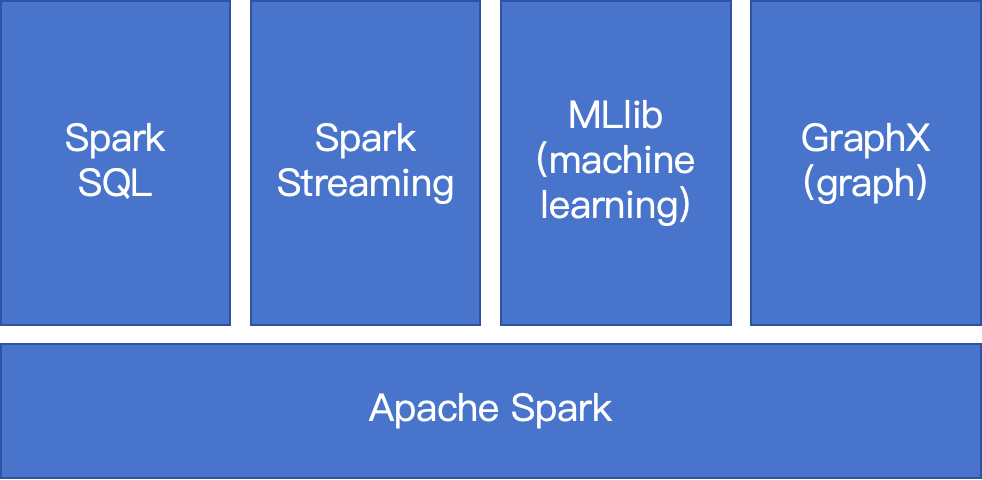
四、Spark和MapReduce编程风格的对比
在编写MapReduce程序时,思考的是map过程和reduce过程的计算逻辑应该怎么实现,所以可以把MapReduce理解为面向过程的大数据计算;而在编写Spark程序时,直接将数据集合抽象成一个RDD对象,思考的是如何在RDD上进行计算,生成新的RDD直至最后的结果,所以可以把Spark理解为面向对象的大数据计算。
(整理自《大数据技术架构:核心原理与技术实践》)













