
『大数据基础』01-大数据技术发展历史和应用场景简析
一、大数据技术发展历史
2004年
Google发表三篇论文,俗称“三驾马车”,内容分别覆盖:
分布式文件系统GFS(Google File System)
大数据分布式计算框架MapReduce
NoSQL数据库系统BigTable
2006年
Hadoop项目从其父项目中剥离出来,成为一个大数据领域的独立项目。Hadoop其实是对Google“三驾马车”的一个实现,其包括分布式文件系统(HDFS)和大数据计算引擎(MapReduce)。
2008年
Facebook发布Hive,支持使用SQL语法来进行大数据计算。Hive会把SQL语句转化成MapReduce的计算程序。
众多Hadoop周边产品出现,形成大数据生态体系:
Sqoop:专门将关系数据库中的数据导入到Hadoop平台;
Flume:针对大规模日志进行分布式收集、聚合和传输;
Oozie:MapReduce工作流调度引擎……
2011年
涌现出HBase、Cassandra等NoSQL数据库产品。HBase是从Hadoop中分离出来的、基于HDFS的NoSQL系统。NoSQL系统主要处理海量数据的存储和访问。
2012年
Yarn项目开始运营,随后发展成为大数据平台上的主流资源调度系统。早期MapReduce又是执行引擎,又是资源调度框架。后来把MapReduce的资源调度能力拆解出来由Yarn承接,MapReduce变成了专门的执行引擎。这就是Yarn的由来。
2012年
推出新的大数据计算框架Spark。Spark相比于MapReduce减少了大量的无谓消耗,使用内存作为运算过程的存储介质,极高提升计算性能,逐步在企业中替代MapReduce。
二、大数据应用场景解析
(一)应用场景分类
按响应的实时性分类
大数据离线计算(批处理计算):用历史数据,进行天、周、月等维度的计算,通常要花费很长的计算时间。有MapReduce、Spark这类的计算框架。
大数据实时计算(流计算):对实时产生的大量数据计算实时的结果。有Storm、Spark Streaming、Flink等流计算框架。
通常情况下采用批处理技术处理历史全量数据,采用流计算处理实时增量数据。
按应用场景进行分类
数据分析:使用Hive、Spark SQL等SQL引擎完成数据的统计分析,主要做报表;
数据挖掘:挖掘数据的潜在价值以进行应用,使用TF、Mahout、MLlib等框架;
机器学习:用已发生的数据,预测即将发生的数据,使用的框架同上。
(二)应用场景发展历史
搜索引擎时代:Google为其搜索引擎而提出的大数据技术原理,专门为搜索引擎处理大量信息,是大数据技术产生的源头。
数据仓库时代:Facebook的Hive推出后,更多的科技企业发现可以方便地利用SQL对本企业的海量数据进行统计分析,因此促进了企业数仓的发展。
数据挖掘时代:大数据应用进入深水区,希望从数据中发现更多潜在的、有价值的信息,而不只是做简单的统计分析。
机器学习时代:与数据挖掘不同的大数据技术深度应用路线,致力于用已有的海量数据来预测即将发生的事情,通常通过训练模型来实现,和人工智能交集的地方。
(三)常见应用场景
医疗、教育、社交媒体、金融、新零售、交通。
三、大数据技术体系结构
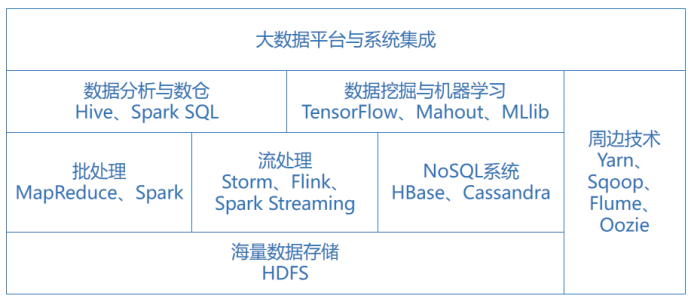
(整理自《大数据技术架构:核心原理与技术实践》)













