
『大数据基础』05-大数据计算:MapReduce既是编程模型也是计算框架
一、既是编程模型,也是计算框架
MapReduce既是编程模型也是计算框架。
对于开发人员来说,MapReduce是编程模型。他们只需要遵循MapReduce编程模型编写逻辑代码,即可交由Hadoop集群计算结果,而无需关注分布式计算过程是如何完成的。
对于Hadoop集群来说,MapReduce是计算框架。开发人员遵循MapReduce编程模型编写的大数据计算程序会通过MapReduce计算框架分发到Hadoop集群中运行,几乎可以实现大数据领域所有的计算需求。
二、经典示例:词频统计程序
/**
* 计数器Mapper
* 在各个DataNode分别统计每个单词出现的次数
*/
public static class CountMapper extends Mapper<Object, Text, Text, IntWritable> {
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer tokens = new StringTokenizer(value.toString());
while (tokens.hasMoreTokens()) {
word.set(tokens.nextToken());
context.write(word, one);
}
}
}/**
* 求和Reducer
* 将所有DataNode统计出来的词频加起来
*/
public static class SumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}以上就是一个依据MapReduce编程模型编写的统计词频示例程序,这个程序在分布式系统上的执行和调度都由MapReduce负责,因此MapReduce不止是编程模型,也是一个计算框架。
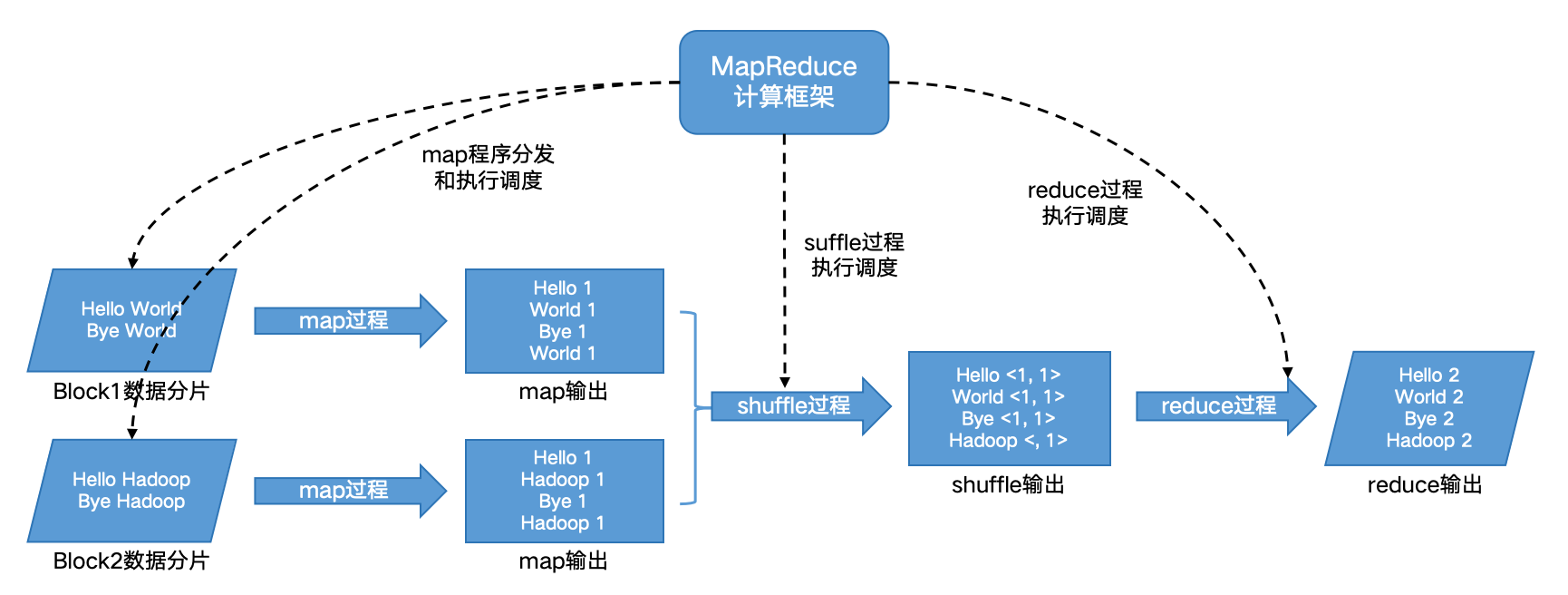
图1 词频统计程序的MapReduce执行过程示意图
MapReduce的数据结构是键值对<Key, Value>。MapReduce分成两个过程:Map和Reduce。
Map:由MapReduce计算框架把程序发往DataNode,以Block的数据作为输入,输出一系列的<Key, Value>。就如上述词频统计程序,Map过程输出是<word, 1>的键值对。
Shuffle:Map和Reduce之间有一个Shuffle过程由MapReduce计算框架自动完成,其作用是把相同Key的键值对从分布式系统中汇聚起来,好进行后续的聚合计算。如上述词频统计会得到<word, <1,1,1,1,......>>的键值对,表示某个单词出现的列表。
Reduce:以Shuffle的结果作为输入,对相同Key的数据集合进行计算,输出想要获得的结果<Key, Value>。如上词频统计会对<word, <1,1,1,1,......>>里的1求和,输出<word, sum>得到该词的词频。
后续文章将进一步深入研究以下两个问题:
代码如何发送到数据块所在服务器,发送后如何启动,启动后如何读取文件块?
不同服务器Map过程输出的<Key, Value>,如何把相同的Key聚合在一起发送给Reduce任务处理。
(整理自《大数据技术架构:核心原理与技术实践》)













