
『大数据基础』07-大数据计算:MapReduce数据合并与连接机制shuffle
一、什么是shuffle
在map过程输出与reduce过程输入的中间,有一个过程叫做shuffle,是MapReduce计算框架处理数据合并与连接的操作。分布式计算需要将不同服务器上的相关数据(根据相同的key)汇集到同一个节点的同一个进程进行下一步计算,这就是shuffle。
二、shuffle过程
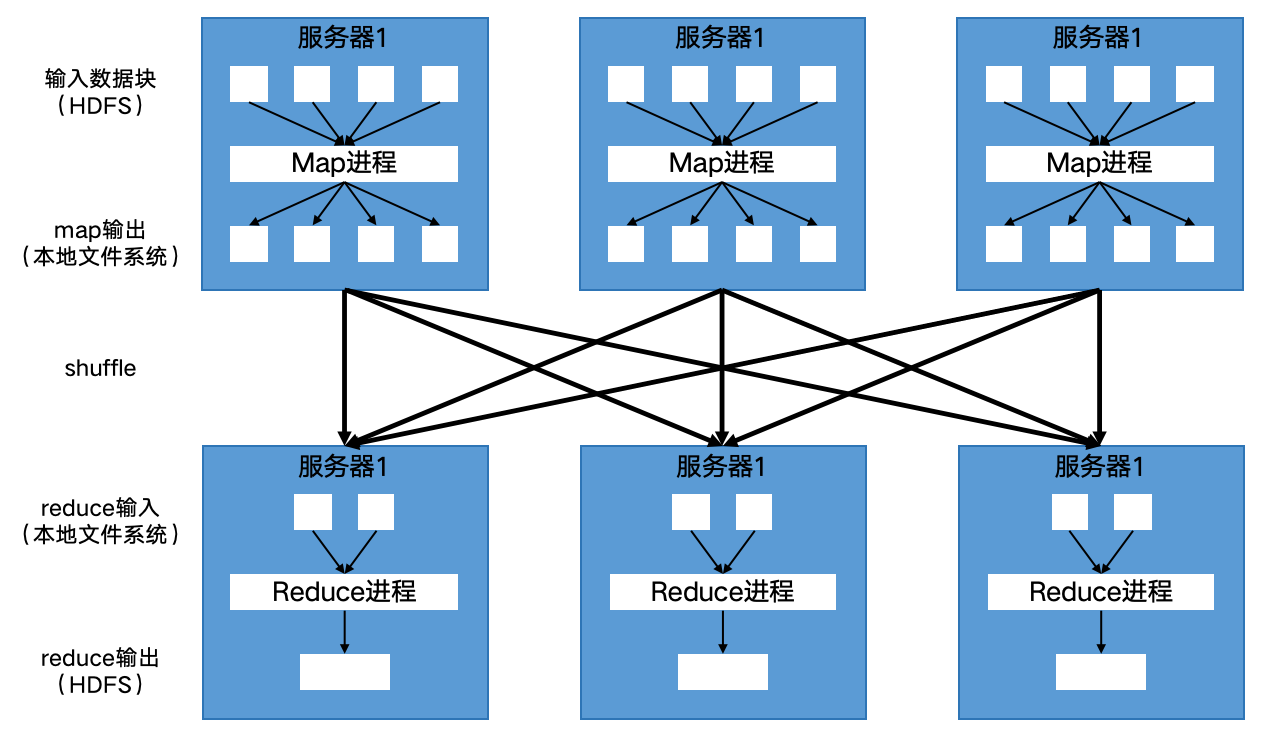
图1 MapReduce的shuffle过程示意图
map计算结果都会先写入map进程所在服务器节点本地文件中(非HDFS而是本地文件系统)。在map进程快完成的时候,MapReduce框架会启动shuffle过程,在map进程调用一个Partitioner接口。此接口的实现逻辑将会对map产生的每个<key, value>进行reduce分区选择,然后通过HTTP通信发送给对应的reduce进程,reduce进程根据此信息访问下一步计算所需的输入数据。
map输出的<key, value>会shuffle到哪个reduce进程是由Partitioner接口的实现来决定的。MapReduce默认用key的哈希值(key.hashCode())对计划拉起的reduce任务数量取模,这样相同的key一定会落在相同的reduce任务ID上。
三、shuffle的意义
shuffle是将分布式的计算结果进行有意义的聚合的必要过程。
不管是MapReduce还是Spark,只要是大数据批处理计算,一定有shuffle。
shuffle是整个MapReduce过程中最难、最消耗性能的地方。
shuffle由大数据计算框架自动完成,开发者无需关注具体实现,但了解shuffle对掌握大数据计算过程是十分必要的。
(整理自《大数据技术架构:核心原理与技术实践》)
阅读建议













