
『大数据基础』04-大数据存储:支持水平伸缩的分布式文件存储系统HDFS
一、回顾:大数据存储面临3个难题
数据存储容量问题:一个文件(一组数据)可能超过一个磁盘的容量。
数据读写速度问题:几十PB数据从磁盘读写可能要天荒地老。
数据可靠性问题:频繁读写易造成磁盘损坏,怎么保证数据可靠。
二、分布式文件存储是大数据计算的基础
Google“三驾马车”论文第一篇的GFS(Google File System)是谷歌内部使用的分布式文件系统。而HDFS(Hadoop Distributed File System)则是开源项目Hadoop的分布式文件系统,因开源被广泛使用。
分布式文件存储是分布式计算的基础。HDFS作为最早的大数据存储系统,已经企业日常事件中存储了非常巨量的数据资产。前面文章说到移动数据的代价是极其庞大的,所以即使HDFS可能不是最好的大数据存储技术,但是数据已经“粘连”在上面,各种新的算法、框架就必须首先支持HDFS才能获取存储在里面的数据。所以大数据技术越发展,越离不开HDFS。
三、HDFS技术原理和架构设计
(一)HDFS设计思路
HDFS采用类似RAID独立磁盘冗余阵列技术的理念,在一个大规模分布式服务器集群上,对数据分片后进行并行读写和冗余存储。整个HDFS的存储空间可以达到PB级。(RAID技术把文件切分存储到不同磁盘上,HDFS把文件切分存储到不同服务器节点上)
(二)HDFS架构设计
HDFS有两个关键概念:数据块(Block)和元数据(MetaData)。
数据块是HDFS中存储数据的基础单位,文件会被分割成多个数据块存储在多个地方。元数据用来记录文件的路径名、数据块ID以及存储位置等信息,通常是一个三元组:(文件路径名,副本数,数据块ID列表)。
HDFS有两个关键组件:NameNode和DataNode。
DataNode负责文件数据的存储和读写操作,HDFS将文件分割成若干Block,每个DataNode存储一部分Block。一个DataNode可以通俗地理解成大数据集群中的一个服务器节点。Block不和服务器磁盘一一对应,一块磁盘可以存储多个Block。HDFS的高可用性机制会把一个Block复制成多分(默认是3份),并将多分副本存储在不同的服务器上。
NameNode负责整个分布式文件系统元数据(MetaData)的管理,相当于操作系统中文件分配表(FAT)的角色。客户端根据这些元数据来访问文件,集群根据这些元数据管理备份、恢复数据。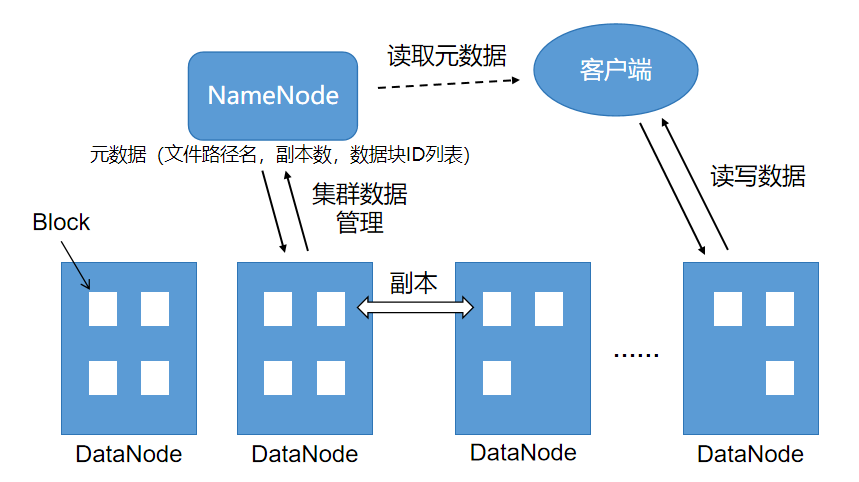
图1 HDFS架构图
(三)HDFS高可用机制
数据存储故障容错(Block级别的容错机制):存储在DataNode上的Block,会计算并存储校验和(checksum),在数据本身出问题时,读取数据计算出来的checksum不正确,就会读取对应的副本。
磁盘故障容错(磁盘级别的容错机制):某块磁盘损坏,其上存储的所有Block ID会被上报给NameNode,NameNode会控制系统复制新的副本,保证副本数量满足要求。
DataNode故障容错(服务器级别的容错机制):如果NameNode超时未能接收DataNode的心跳信号,NameNode判断该服务器宕机,会从元数据读取其上存储的Block,在其他可用机器上复制新的副本。
NameNode故障容错(集群级别的容错机制):NameNode是整个HDFS控制调度的核心,采用主从热备的方式实现高可用。两台NameNode服务器通过Zookeeper选举确定主服务器。正常运行时,两台NameNode服务器之间通过共享存储系统Shared Edits来同步元数据。当主NameNode宕机时,Zookeeper把从NameNode升级成主NameNode。
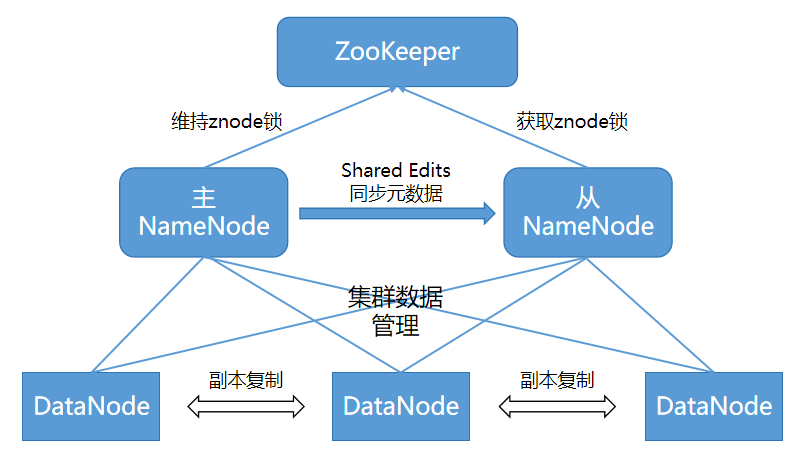
图2 NameNode主从热备高可用架构
四、题外话:分布式系统的常用高可用策略
冗余备份:任何程序、数据都至少有一个备份。磁盘之间、服务器之间,甚至到数据中心之间都有可能做备份。
失效转移:当程序或数据无法访问时,将请求转移到正常的服务器上,这就是失效转移。注意失效的判定,如果错误判定失效可能造成“脑裂”混乱现象出现,就像主从NameNode同时向DataNode发送请求。Zookeeper的选举机制能解决这个问题。
限流和降级:大量用户请求到来无法及时处理会耗尽系统资源。应对思路有两种:一是拒绝部分请求以保证系统资源不溢出,即限流;二是关闭部分主链路以外的不必要的辅助功能,减少系统资源消耗。二者的区别在于降级通常用在可预知的场景,比如做活动前先关闭一些功能。
(整理自《大数据技术架构:核心原理与技术实践》)













